

 Microsoft sort Visual Studio Tools for Git
Microsoft sort Visual Studio Tools for Gitune extension pour intégrer les fonctions de gestion de versions de Git dans Visual Studio et TFS
Microsoft accentue le support de Git, loutil open source de gestion de versions décentralisé, dans Visual Studio et Team Foundation Server (TFS).
La firme a publié récemment une nouvelle version de lextension Visual Studio Tools for Git, qui apporte à lenvironnement de développement un ensemble doutils et fonctionnalités pour le contrôle de versions des applications.
Lextension Visual Studio Tools for Git permet lintégration et la gestion de nimporte quel dépôt Git dans Visual Studio. Elle fournit des outils qui permettent de travailler avec des services comme GitHub. Loutil offre un suivi automatique des changements dans une solution Visual Studio, affiche létat des fichiers dans lexplorateur, dispose des fonctions de gestion des commits et des branches, etc.
Le changement phare dans cette mouture réside dans des améliorations significatives de la vitesse. Cette version promet des outils plus rapides pour les commits, les « push » et de meilleures performances lors des travaux sur des repository de grandes tailles.
Selon les tests effectués par Microsoft, lenvoi de 10 fichiers dun kilotects a permis de constater un gain de performances pouvant atteindre 4 765 %.
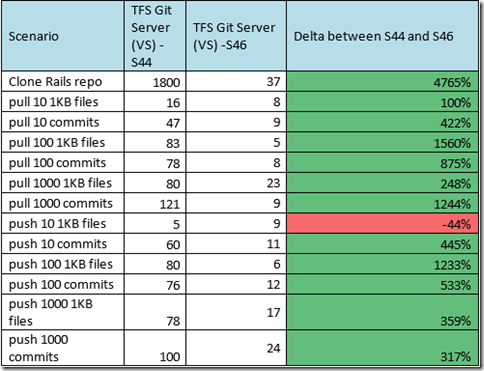
On notera également des correctifs de bogues, une meilleure gestion de CRLF (saut de ligne), le support des sous-modules du projet libgit2, une meilleure prise en charge de lauthentification pour Windows et bien plus.
Visual Studio Tools for Git est compatible avec Visual Studio 2012 Update 2 et Team Foundation Server 2012 Update 2.

 Télécharger Visual Studio Tools for Git
Télécharger Visual Studio Tools for GitSource : MSDN
Et vous ?
Utilisez-vous Git ? Que pensez-vous de son support dans Visual Studio ?
Vous avez lu gratuitement 5 586 articles depuis plus d'un an.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.



