

 Google parvient à synthétiser une voix (presque) humaine,
Google parvient à synthétiser une voix (presque) humaine, grâce à la technologie WaveNet développée par sa filiale londonienne DeepMind
DeepMind, la filiale londonienne de Google spécialisée dans lintelligence artificielle qui sest déjà illustrée en développant lintelligence artificielle qui a battu Lee Sedol au jeu de go, a présenté les premiers résultats de sa mise au point de la technologie WaveNet qui produit une voix ressemblant à celle de lhumain.
Dans un billet de blog, elle explique que « permettre aux gens de converser avec des machines est un rêve de longue date dans l'interaction homme-ordinateur. La capacité des ordinateurs à comprendre le langage naturel a été révolutionnée au cours des dernières années par l'application des réseaux de neurones profonds (par exemple, avec Google Voice Search). Cependant, la génération du discours des ordinateurs - un processus généralement désigné comme étant la synthèse vocale ou text-to-speech (TTS) - est encore largement basée sur ce qu'on appelle les TTS concaténatives, où des fragments vocaux courts d'une très grande base de données sont enregistrés sur un seul haut-parleur, puis recombinés pour former des énoncés complets. Cela rend difficile la modification de la voix (par exemple le passage à un haut-parleur différent, la modification de laccent ou l'émotion du discours) sans avoir à enregistrer une toute nouvelle base de données ».
DeepMind explique que cela a conduit à une grande demande de paramétriques TTS, où toutes les informations requises pour générer les données sont stockées dans les paramètres du modèle, sans compter le fait que le contenu et les caractéristiques de la parole peuvent être contrôlés via les entrées du modèle. Jusqu'à présent, cependant, les paramétriques TTS ont tendance à paraître moins naturels que les TTS concaténatives, du moins pour les langues syllabiques (langues dans lesquelles ce sont les syllabes qui rythment la phrase) telles que l'anglais. Précisons que la plupart des langues romaines (à linstar du français, de litalien ou de lespagnol) appartiennent à cette catégorie. Les modèles paramétriques existants génèrent habituellement des signaux audio en se servant dalgorithmes de traitement de signaux appelés vocodeurs.
WaveNet est venu modifier ce paradigme en modélisant directement la forme d'onde brute du signal audio, un échantillon à la fois. Lavantage de se servir des formes dondes brutes permet non seulement à WaveNet de donner aux paroles synthétiques une sonorité plus naturelle, mais en plus il lui permet également de modéliser tout type daudio, y compris la musique.
DeepMind explique avoir entraîné WaveNet en se servant de certains des ensembles de données TTS de Google afin de pouvoir évaluer sa performance. Le résultat a été à la hauteur des attentes de DeepMind : sur une échelle de 1 à 5, pour le Mandarin et lAnglais US, la technologie WaveNet et la voix humaine ont presque la même note sur la mesure MOS (Mean Opinion Scores, une mesure standard pour des tests subjectifs de qualité sonore qui a été obtenu dans des tests à laveugle avec des sujets humains). La technologie se démarque dailleurs des systèmes TTS de Google pour le mandarin et laméricain, considérés comme étant parmi les meilleurs au monde.
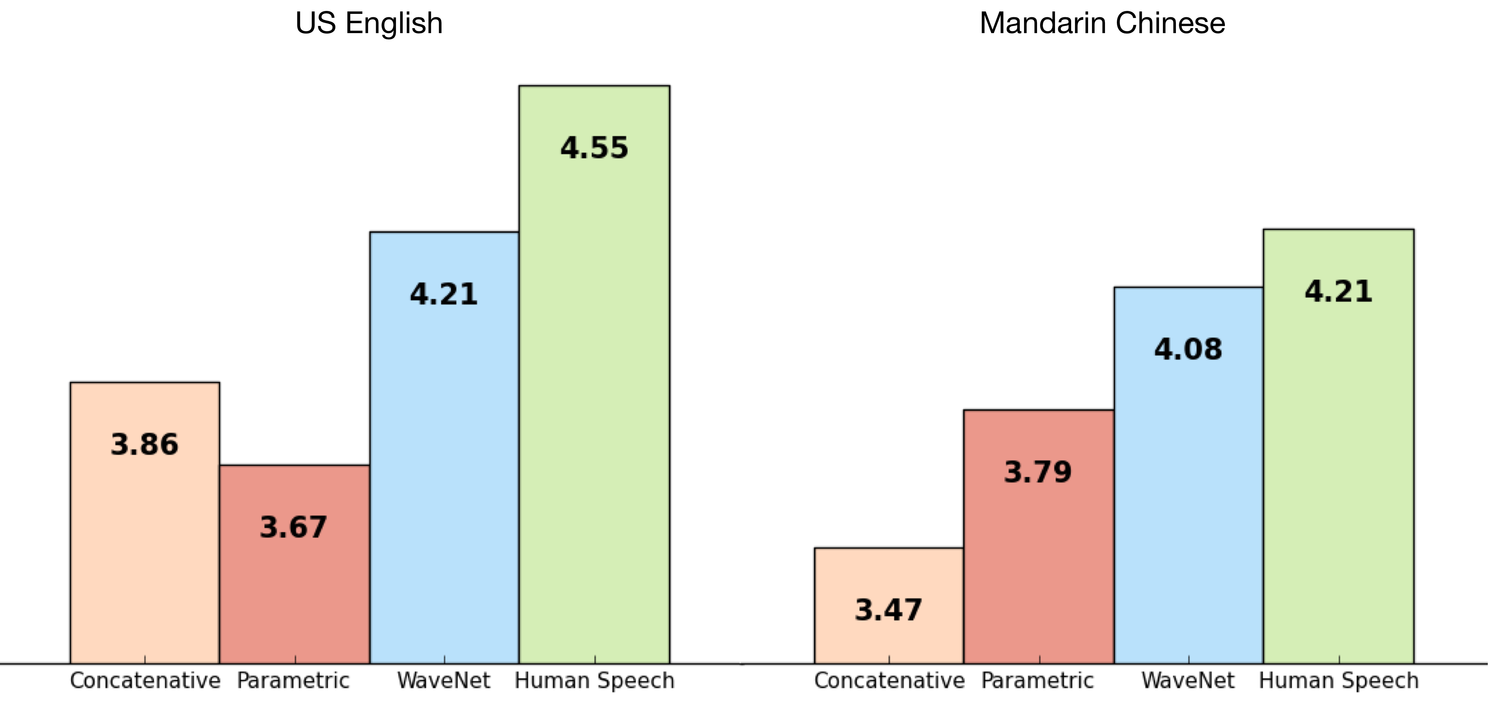
Le résultat est impressionnant : la voix synthétisée par WaveNet se rapproche indubitablement de la voix humaine. DeepMind explique que les sons non vocaux, tels que la respiration ou les mouvements de la bouche, sont eux aussi parfois générés par WaveNet, ce qui reflète la grande flexibilité des modèles de données audio brutes. Un échantillon de la voix synthétisée par WaveNet est disponible à titre de comparaison avec les techniques existantes.
Source : WaveNet
Voir aussi :
 DeepMind développe une intelligence artificielle capable d'apprendre à jouer à 49 jeux Atari 2600 Jeu de Go : les développeurs s'imposent face à Lee Sedol, l'IA de Google terrasse la star du Go par un score de 4-1
DeepMind développe une intelligence artificielle capable d'apprendre à jouer à 49 jeux Atari 2600 Jeu de Go : les développeurs s'imposent face à Lee Sedol, l'IA de Google terrasse la star du Go par un score de 4-1
Vous avez lu gratuitement 10 053 articles depuis plus d'un an.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.

